Ngoài Covíd 19 và blog thefullsnack đóng cửa làm publicity stunt ra thì cuối 2019, đầu 2020 còn là thời kì của trao lưu RIIR (Rewrite It In Rust).
Cuối năm 2019, cộng đồng webuild đang sôi sục về chủ đề gõ tiếng Việt trên “lai nớt” thì có 2 cá nhân nảy ra cùng ý tưởng nhưng giấu nhẹm đi làm riêng. Ý tưởng là 1 bộ Input Method Editor hoàn toàn bằng Rust, hứa hẹn sẽ có thể cạnh tranh với các tên tuổi trong làng gõ chữ Quốc ngữ trên Linux như ibus hay fcitx.
Sau khi kế hoạch 2 bên bại lộ thì vị tiền bối kia đã chọn giao lại trọng trách này cho mình thực hiện. (vị tiền bối mình đang nói tới chưa bao giờ thấy ở trong cùng 1 căn phòng với chủ blog thefullsnack )
Tuy nhiên, sau nhiều ngày thử nghiệm với cơ chế receive và sending key trên X11, thậm chí là sử dụng luôn cả evdev và uinput để nhận và send key thẳng vào kernel Linux, nhưng tần suất chửi thề của mình vẫn không thuyên giảm (Cái này mình sẽ nói ở một bài riêng). Nhận thấy trình độ thấp kém, mình đành ngậm ngùi nhận thua và chuyển từ phát triển IME sang làm library giúp đặt dấu cho IME. Mong là có thể giúp ích cho các vị cao nhân trong tương lai sử dụng library của mình mà hoàn thành trọng trách bị mình bỏ dở.
Ở post này mình sẽ nói sơ qua quy luật đặt dấu mà mình học được và đồng thời giới thiệu library hỗ trợ đặt dấu do mình phát triển.
Các phần của 1 chữ tiếng Việt
Disclaimer! Mình vốn không xuất thân từ ngành ngôn ngữ học, điểm văn lại chưa bao giờ qua 6.5 từ hồi cấp 2 tới giờ nên những gì mình tìm hiểu được có thể không chính xác cho lắm.
Để hiểu về quy luật bỏ dấu này, các bạn không cần đi sâu vào tiếng Việt mà chỉ tập trung chủ yếu phần âm vị học.
Âm tiết
Trong tiếng Việt, đơn vị phát âm nhỏ nhất gọi là âm tiết [1]. Tuy nhiên, cũng có tài liệu cho rằng phần này gọi là âm hoặc tiếng. Có thể hiểu, 1 âm tiết là 1 chữ khi phát âm.
Theo bài viết của tác giả Vũ Xuân Lương (vietlex)[2]:
Âm tiết là đơn vị phát âm tự nhiên nhỏ nhất trong ngôn ngữ. Trong tiếng Việt, một âm tiết bao giờ cũng được phát ra với một thanh điệu, và tách rời với âm tiết khác bằng một khoảng trống (space). Trên chữ viết, mỗi âm tiết tiếng Việt được ghi thành một “chữ” . Vd: “hoa hồng bạch” gồm 3 chữ hoặc 3 âm tiết.
Nguyên âm
Trong mỗi âm tiết, đều có 1 phần nguyên âm bao gồm 1 hoặc nhiều chữ cái nguyên âm hợp lại. Các chữ cái nguyên âm bao gồm:
a, ă, â, e, ê, i, o, ô, ơ, u, ư, y
Phụ âm
Phụ âm bao gồm phụ âm đầu và phụ âm cuối. Đây là phần chỉ bao gồm các chữ cái phụ âm nhưng với vài trường hợp ngoại lệ, tổ hợp phụ âm có thể bao gồm chữ cái phụ âm lẫn nguyên âm. Ví dụ, các chữ cái phụ âm có thể bao gồm:
b, c, d, đ, vv…
và tổ hợp phụ âm có thể là:
ch, gh, kh, ng, gi, qu, vv…
Để ý với tổ hợp “qu”, tuy “u” là kí tự nguyên âm nhưng khi đi chung với “q” nó lại trở thành một phần tạo nên phụ âm “qu”.
Cấu trúc của âm tiết
Cấu trúc của 1 âm tiết có thể hình dung như sau:
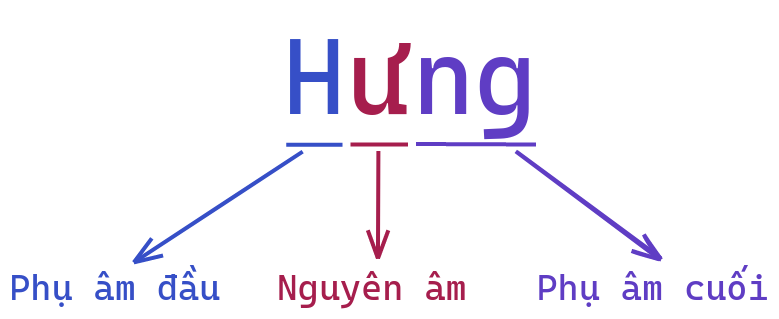
Tuy nhiên, 1 âm tiết không nhất thiết phải bao gồm phụ âm đầu lẫn phụ âm cuối. Ví dụ, chữ “ưng” trong “ưng ý” không hề có phụ âm đầu, hay chữ “hư” không tồn tại phụ âm cuối.
Kí tự riêng của tiếng Việt
Ngoài việc sử dụng các kí tự latin, trong tiếng Việt còn tồn tại những kí tự riêng. Chúng ta có tổng cộng 7 kí tự riêng, với 4 kí tự có dấu tách biệt như ă â ê ô và 3 kí tự có dấu nối liền như đ, ơ và ư [4].
Nếu các bạn hứng thú với lịch sử chữ Quốc ngữ, cũng như typography của tiếng Việt, thì đừng bỏ qua cuốn Vietnamese Typography của tác giả Donny Trương.

Một phần của trang giới thiệu lịch sử tiếng Việt trên trang Vietnamese Typography
Các quy luật đặt dấu
Sau khi tham khảo nhiều bài viết thì mình quyết định kết hợp 2 bảng quy luật từ 2 nguồn là bài “Quy tắc đặt dấu thanh trong tiếng Việt” của tác giả Vũ Xuân Lương và từ một trang của một tác giả lấy tên là Johannjs[3]. (Fun fact: Mình đang gõ bài viết này bằng công cụ gõ cực xịn trên trang đó).
Chúng ta có 6 quy luật khi đặt dấu thanh. Các quy luật này được áp dụng từ trên xuống theo trình tự chứ không áp dụng ngẫu nhiên:
1. Dấu thanh luôn luôn đặt ở nguyên âm.
Với quy luật này, chúng ta có thể loại bỏ phần phụ âm và chỉ xét phần nguyên âm. Trong rất nhiều trường hợp, 1 chữ chỉ bao gồm 1 kí tự nguyên âm, ví dụ “hà”, “quý”, “chung” nên chúng ta có thể giảm thiểu đáng kể độ phức tạp của thuật toán đặt dấu
2. Nếu một từ có chứa kí tự “ơ”, dấu thanh sẽ đặt ở kí tự đó.
Quy luật này giúp giải quyết tình huống phần nguyên âm có 2 kí tự nguyên âm trở lên và bao gồm kí tự “ơ”. Ví dụ “ước”, “phước”, “tưới”.
3. Nếu nguyên âm bao gồm 1 kí tự riêng, dấu thanh sẽ được đặt vào kí tự đó.
Kí tự riêng hay, kí tự mang dấu phụ như mình nói ở phần trước, nếu có xuất hiện trong phần nguyên âm, nó sẽ được ưu tiên đặt dấu đầu tiên. Ví dụ, chữ “hiện” bao gồm “iê” trong phần nguyên âm, và vì, “ê” là kí tự riêng nên chúng ta ưu tiên đặt dấu nặng vào “ê” thay vì “i”.
4. Nếu một từ có chứa cặp nguyên âm “oa”, “oe”, “oo”, “oy”, dấu thanh sẽ được đặt ở nguyên âm thứ 2.
Quy luật này giúp ta xử lý các trường hợp như “loá”, “xoè” hay “tuỵ”. Lưu ý, các từ với cặp “oo”, dấu thanh vẫn được để trên chữ cái thứ 2. Ví dụ: quần soọc, xe rơ moóc.
5. Nếu một từ kết thúc bằng 2 hoặc 3 con chữ nguyên âm, dấu thanh sẽ được đặt ở chữ cái nguyên âm áp chót.
Ví dụ: ngoẻo, ngoáy, chịu, của, vv…
6. Chữ cái nguyên âm nào đứng đầu từ trái đếm qua thì dấu thanh sẽ được đặt ở chữ cái đó.
Nếu tất cả các quy luật trên đều không thể áp dụng, thì dấu thanh sẽ được đặt lên chữ cái nguyên âm đầu tiên.
Quảng cáo
Tất nhiên bạn có thể tự implement các quy luật kia làm IME, nhưng tại sao phải “reinvent the wheel” khi các bạn đã có library viết bởi author bài viết mà bạn vừa skip xuống đáy vì dài quá đéo đọc?
Sơ lược về library VI
Như đã nói ở trên, mình vốn chủ định VI là một IME, nhưng vì không tìm ra được cách hiệu quả để listen và send key trên Linux nên mình quyết định chuyển nó thành 1 library hỗ trợ cho việc phát triển IME.
Quy trình đặt dấu thanh của library diễn ra như sau:
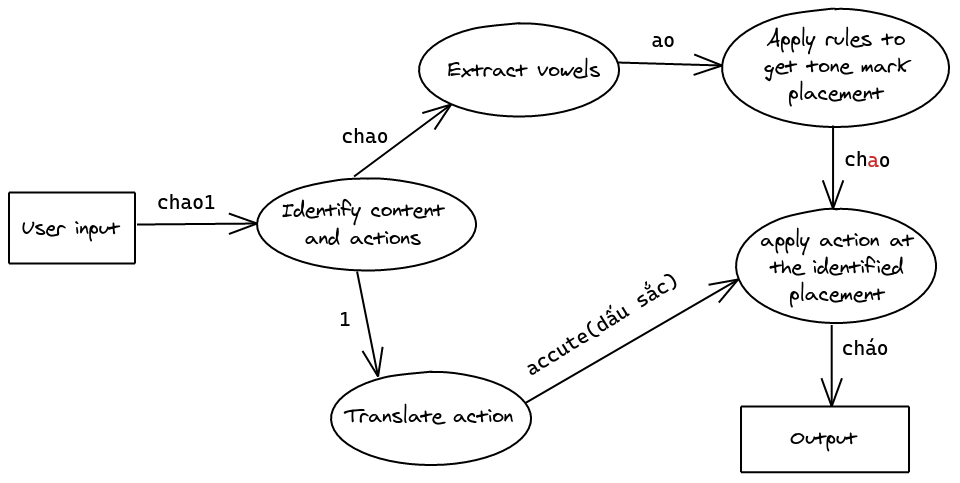
Tách action và content
User input sẽ bao gồm 2 phần là action và content. Ví dụ, chao1 thì content sẽ là chao và kí tự 1 theo kiểu gõ VNI là để đặt dấu sắc, mình gọi đó là một action.
Tìm nguyên âm
Content sau khi được tách ra sẽ được xử lý để tìm ra phần nguyên âm. Cách làm thì khá đơn giản, chỉ cần skip phần phụ âm đầu (nếu có) và lấy những kí tự tiếp theo cho đến khi đụng phụ âm cuối hoặc kết thúc chữ.
Lưu ý: Trường hợp “gi” và “qu”, dù “i” và “u” là chữ cái nguyên âm nhưng đây là trường hợp ngoại lệ nên “gi”, “qu” là cặp phụ âm đầu.
Tìm vị trí đặt dấu thanh
Sau khi đã tìm ra phần nguyên âm, library sẻ áp dụng 6 quy luật trên để tìm vị trí đặt dấu thanh.
Chuyển ký tự thành action
Khi tách ký tự khỏi user input, library sẽ chuyển kí tự thành action. Ví dụ, “1” thành dấu sắc, “2” thành dấu huyền, vv…
Đặt dấu thanh
Ở giai đoạn này, library đã tìm được vị trí đặt dấu thanh cũng như loại dấu thanh cần đặt. Bước cuối cùng này replace kí tự ở vị trí đặt dấu thanh với một kí tự có chứa dấu thanh…bởi vì trình độ khoa học hiện tại chưa cho phép đánh cái dấu lên chữ thôi mà phải replace luôn bằng character khác.
Nghe hay đó, coi thêm ở đâu?
Hiện library mình đang open-source ở gihub. Mong các bạn có dịp ghé qua ủng hộ ý kiến
https://github.com/ZeroX-DG/vi-rs
Tham khảo
- ngonngu.net. (2006). Âm tiết và đặc điểm âm tiết tiếng Việt.
- Vũ Xuân Lương. (2020). Quy tắc đặt dấu thanh trong tiếng Việt.
- Johannjs. (2003). The right place of the Vietnamese accent.
- Donny Trương. (2018). Vietnamese Typography.
- Trần ngọc Dung. (2016). Vần & Cách Ráp Âm Trong Tiếng Việt.